헤더 파일
- Visual Studio에서는 math.h 파일을 include 하지 않아도 pow 함수를 사용할 수 있지만
백준 환경에서는 math.h 파일을 include 하지 않고 pow 함수 사용 시 컴파일 오류가 난다.
변수 할당
- int : 4바이트 (-231 ~ 231-1) (약 -20억 ~ 약 20억)
- unsigned int : 4바이트 (0 ~ 232-1)
- long : 4바이트 (-231 ~ 231-1)
- long long : 8바이트 (-263 ~ 263-1)
- 더 큰 자료형 없음
변수 초기화
int arr[10];
int arr[10] = { 1, };- 전역 변수를 첫째 줄처럼 선언하면 0이나 false와 같은 default value로 초기화되는 것이 보장된다는 의견과 보장되지 않는다는 의견이 분분하다.
- 둘째 줄처럼 초기화하면, 배열 내 모든 요소가 1로 초기화될 것 같지만, 실제로는 0번째 요소만 1로 초기화 된다.
- 프로그래머스 플랫폼에서는 {0, }로 초기화 하면 모두 0으로 초기화되는 듯 하다 (경험상 그런 것이니 확실치는 않음)
memset(arr, 0, sizeof(arr));
memset(arr, -1, sizeof(arr));- 0이나 -1로 초기화할 때는 memset으로 초기화하는 것이 안전하고 빠르다. (0과 -1 이외의 숫자는 오류 발생)
- memset()은 <string.h>라는 헤더 파일 필요
vector <int> ans(N, -1);- vector를 초기화할 때는, 위와 같이 하면, 크기가 N인 벡터의 모든 요소가 -1로 초기화된다.
vector<vector<int>> v(6, vector<int>(3, 10));
cout << v[0][0] << endl;
cout << v[1][2] << endl;
cout << v[5][1] << endl;
cout << v[2][5] << endl; // out of index실행 결과
10
10
10- 2차원 벡터의 초기화 방법이다.
입출력
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);위의 코드를 쓰지 않으면 cin와 cout이 성능을 떨어뜨린다.
뿐만 아니라 endl도 성능을 더욱 떨어뜨린다.
그래서 endl 대신 \n를 쓰면 성능이 좋아진다.
위의 방법들을 써도 시간 초과가 나는 경우에는
그냥 printf를 쓰는 게 제일 빠르다.
참고로, 백준 1874번과 2751번 같은 경우
scanf보다는 오히려 cin.tie(NULL)을 적용한 cin가 더 빨랐다.
문자/문자열
- str.substr(0, 3);
* 0번째 index부터 3글자
- str.find('a');
- stoi('123');
* string to int
* #include <string> 필요
- to_string(123);
* int to string
* #include <string> 필요
- (int) '5'
* char to int : 아스키 코드 값
- '5' - '0'
* char to int : '5'를 5로 변환
- (char) 65;
* int to char : 65를 'A'로 변환
- 8 + '0'
* int to char: 8를 '8'로 변환
- getline(cin, str);
* 한 문장 입력
- sort(vec.begin(), vec.end());
* 사전 순 정렬
* #include <algorithm> 필요
- 알파벳 개수 = 26개
- char 타입끼리 사칙연산
* 숫자 타입으로 바뀜 ex) '5' - '0' = 5 / 'c' - 'a' = 2
- size() - 1
* size()는 unsigned int를 리턴하므로c size()-1는 -1가 아니라 4294967295임을 주의 (특히 for문의 조건문에서 주의)
- string 타입을 const char* 타입으로 형변환
* string cppStr = "CPPstring";
* const char* cStr = cppStr.c_str()
* printf("%s\n", cppStr.c_str());
- split by character
#include <iostream>
#include <vector>
#include <string>
using namespace std;
vector<string> split(string str, vector<char> characters) {
vector<string> splited_strs;
int idx = 0;
int i = 0;
for (; i < str.size(); i++) {
bool flag = false;
for (int j = 0; j < characters.size(); j++) {
if (str[i] == characters[j]) flag = true;
}
if (flag == true) {
splited_strs.push_back(str.substr(idx, i - idx));
idx = i + 1;
}
}
splited_strs.push_back(str.substr(idx, i - idx));
return splited_strs;
}
int main() {
string str; cin >> str; // 55-50+40
vector<char> v;
v.push_back('+');
v.push_back('-');
vector<string> strs = split(str, v);
for (int i = 0; i < strs.size(); i++) {
cout << strs[i] << endl;
}
/* 출력결과
55
50
40
*/
return 0;
}
정렬
- #include <algorithm> 선언하고 sort 함수 사용
- sort 함수는 quick sort 기반으로 평균 O(nlogn), 최악 O(n^2)임
* 배열
int arr[10];
sort(arr, arr+10);
* 벡터
vector<int> vec;
sort(vec.begin(), vec.end());
- 오름차순 정렬
sort(A.begin(), A.end());또는
sort(A.begin(), A.end(), less<int>());- 내림차순 정렬
sort(B.begin(), B.end(), greater<int>());- 비교 함수의 customizing
* bool 타입 리턴
* a -> b 순서로 정렬하고 싶으면 return a < b 또는 a - b < 0
sort(dq.begin(), dq.end(), comp);bool comp(pair<int, int> a, pair<int, int> b) {
if (a.second == b.second) return a.first < b.first;
else return a.second < b.second;
}- 순서 뒤집기
reverse(arr, arr + size);
수열에서 최소 / 최대
#include <iostream>
#include <algorithm>
#include <list>
#include <vector>
using namespace std;
int arr[6] = { 3, 2, 1, 6, 4, 5 };
list<int> my_list = { 3, 2, 1, 6, 4, 5 };
vector<int> v = { 3, 2, 1, 6, 4, 5 };
int main() {
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
cout << *min_element(arr, arr + sizeof(arr) / sizeof(int)) << endl;
cout << *max_element(my_list.begin(), my_list.end()) << endl;
cout << *min_element(v.begin(), v.end()) << endl;
return 0;
}출력 결과 :
1
6
1
대소 비교
#include <iostream>
#include <algorithm>
using namespace std;
int main() {
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
cout << "min(1, 2) : " << min(1, 2) << endl;
cout << "min(2, 2) : " << min(2, 2) << endl;
cout << "min('b', 'd') : " << min('b', 'd') << endl;
cout << "min(34.5, 12.3) : " << min(34.5, 12.3) << endl << endl;
cout << "max(1, 2) : " << max(1, 2) << endl;
cout << "max(2, 2) : " << max(2, 2) << endl;
cout << "max('b', 'd') : " << max('b', 'd') << endl;
cout << "max(34.5, 12.3) : " << max(34.5, 12.3) << endl;
return 0;
}출력 결과 :
min(1, 2) : 1
min(2, 2) : 2
min('b', 'd') : b
min(34.5, 12.3) : 12.3
max(1, 2) : 2
max(2, 2) : 2
max('b', 'd') : d
max(34.5, 12.3) : 34.5- INT_MAX와 INT_MIN은 <limits.h>라는 헤더 파일에 있음
계산
- pow(2, 4);
* 2의 4승 = 16
* #include <cmath> 필요
- sqrt(4);
* 루트 4 = 2
* #include <cmath> 필요
- abs(4); abs(4.21);
* #include <cstdlib>
1) int abs(int num);
2) long int abs(long int num);
3) long long int abs(long long int num);
* #include <cmath>
1) double abs(double num)
2) float abs(float num)
3) long double abs(long double num)
4) double abs(T x);
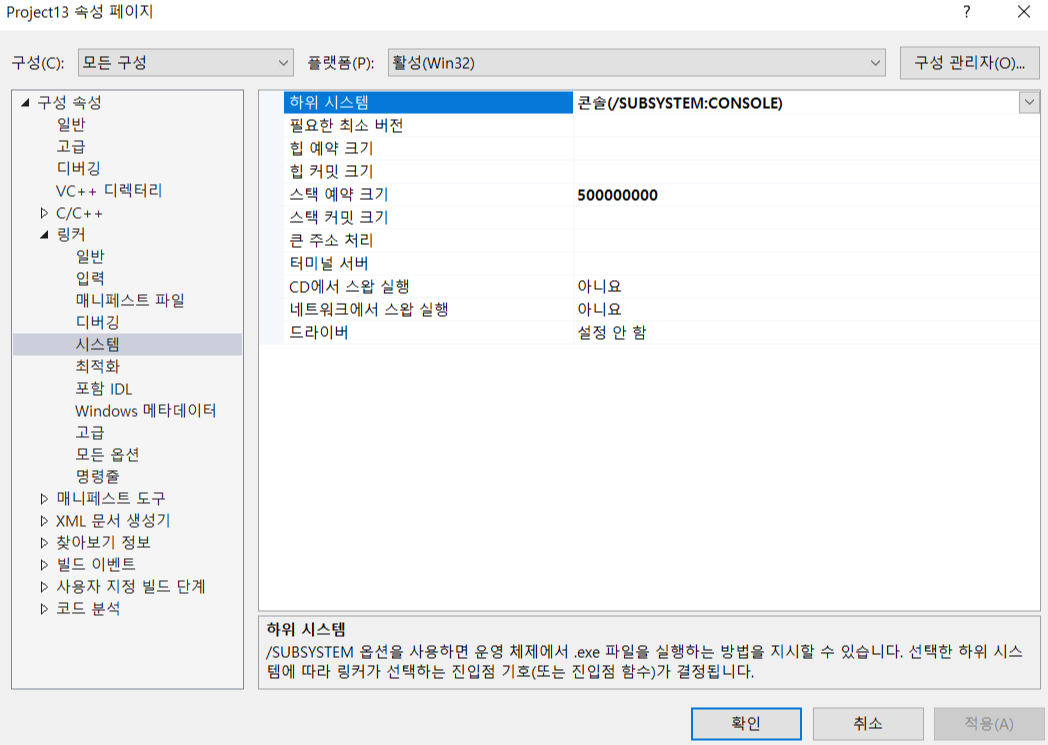
스택 오버플로우
1) 재귀 함수 과다 호출
2) 지역 변수 과다 할당
-> 기본 스택 사이즈인 1MB 초과 할당 시, 스택 오버플로우로 프로그램 멈춤
-> Visual Studio 기준, '속성 - 링커 - 시스템 - 스택 예약 크기'를 통해 스택 사이즈 수동 조절 가능 (단위 : Byte)
STL 활용
삼성 역량 테스트 B형을 제외한 대부분의 코딩 테스트에서는 모든 STL이 사용 가능하므로
탐색, 정렬, 트리 등을 직접 구현할 필요 없이 STL의 사용법만 익혀 놓으면 된다.
단, 기술면접에서는 각 자료 구조와 알고리즘에 대한 세부 사항을 물어볼 수 있으니
내부 구조와 구현 방법, 동작 원리, 시간 복잡도 비교 등은 알고 있어야 한다.
익혀야 할 주요 STL : vector, map, set, lower_bound, upper_bound, next_permutation, sort, iterator 등
자료구조
1) priority_queue
- #include <queue> 선언하여 사용
- 주요 멤버 함수 : size(), empty(), push(), pop(), top()
priority_queue<int> pq; // 자료형만 썼을 때 아래와 같은 default 값이 적용된다.
priority_queue<int, vector<int>, less<int>> pq; // less than operator 사용- default가 최대힙(우선순위가 높을수록 큰 값)이다. 즉 less<int> (오름차순) 사용
- 최소힙(우선순위가 높을수록 작은 값)을 사용하려면 greater<int> (내림차순) 사용
priority_queue<pair<int, int>> pq;
priority_queue<pair<int, int>, vector<pair<int, int>>, less<pair<int,int>> pq;- pair타입은 first를 기준으로 정렬됨
- custom comparator 사용법
typedef pair<int, int> my_type;
struct comp {
bool operator()(my_type& a, my_type& b) {
if (a.first == b.first) return a.second > b.second;
else return a.first > b.first;
};
};
priority_queue<my_type, vector<my_type>, comp> pq;- 시간 복잡도
1) 삽입
* 배열/연결리스트 : O(n)
* 힙 : O(log2n)
2) 삭제
* 배열/연결리스트 : O(1)
* 힙 : O(log2n)
2) deque
- #include <deque> 선언하여 사용
- 주요 멤버 함수 : size(), empty(), at(), front(), back(), push_front(), push_back(), pop_front(), pop_back(), insert(), erase()
- 시간 복잡도
* at : O(1)
* push_front : amortized O(1)
* push_back : amortized O(1)
* pop_front : amortized O(1)
* pop_back : amortized O(1)
* insert : O(n)
* erase : O(n)
3) vector
- #include <vector> 선언하여 사용
- 주요 멤버 함수 : size(), empty(), at(), front(), back(), push_back(), pop_back(), insert(), erase()
- 시간 복잡도
* at : O(1)
* push_back : amortized O(1)
* pop_back : amortized O(1)
* insert : O(n)
* erase : O(n)
- erase의 활용
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
void show(vector<int>& v) {
for (int i = 0; i < v.size(); i++) {
cout << v[i] << " ";
}
cout << endl;
}
int main() {
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
// 초기화
vector<int> v = { 0,0,4,0,0,0,0,4,0,0,4,0,4,4,4,0,0,0 };
show(v);
// 첫번째 4 제거
v.erase(find(v.begin(), v.end(), 4)); // find()는 O(n)
show(v);
// 모든 4 제거
v.erase(remove(v.begin(), v.end(), 4), v.end()); // remove()는 header file <algorithm> 필요
show(v);
return 0;
}출력결과
0 0 4 0 0 0 0 4 0 0 4 0 4 4 4 0 0 0
0 0 0 0 0 0 4 0 0 4 0 4 4 4 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
4) map
- #include <map> 선언하여 사용
- key, value 쌍으로 저장 : key에는 primitive type(int, long, char, double) 모두가 들어갈 수 있음
- key 중복 불가 : multimap으로 key 중복 가능
- 균형이진탐색트리(AVL트리) 구조 : 삽입/삭제 시마다 정렬 수행
- 시간 복잡도
* 검색/삽입/삭제 : O(logn)
* 단, key가 크기가 m인 string 타입인 경우 : O(mlogn)
map<int, string> get_by_int;
map<string, int> get_by_string;
// 삽입
for (int i = 0; i < N; i++) {
string temp; cin >> temp;
get_by_int[i] = temp;
get_by_string[temp] = i;
}
// 검색
string str = get_by_int[245];
int num = get_by_string["key"];
- 또 다른 insert 방법
get_by_string.insert(pair<string, int>("key", 27));- 상세한 사용법 (출처 : twpower.github.io/91-how-to-use-map-in-cpp)
* iterator(반복자)
→ begin(): beginning iterator를 반환
→ end(): end iterator를 반환
* 추가 및 삭제
→ insert(make_pair(key, value)): 맵에 원소를 pair 형태로 추가
→ erase(key): 맵에서 key(키값)에 해당하는 원소 삭제
→ clear(): 맵의 원소들 모두 삭제
* 조회
→ find(key): key(키값)에 해당하는 iterator를 반환
→ count(key): key(키값)에 해당하는 원소들(value들)의 개수를 반환
* 기타
→ empty(): 맵이 비어있으면 true 아니면 false를 반환
→ size(): 맵 원소들의 수를 반환
#include <iostream>
#include <string>
#include <map>
using namespace std;
int main() {
map<string, int> m;
m.insert(make_pair("a", 1));
m.insert(make_pair("b", 2));
m.insert(make_pair("c", 3));
m.insert(make_pair("d", 4));
m.insert(make_pair("e", 5));
m["f"] = 6; // also possible
m.erase("d");
m.erase("e");
m.erase(m.find("f")); // also possible
if (!m.empty())
cout << "size: " << m.size() << '\n';
cout << "a: " << m.find("a")->second << '\n';
cout << "b: " << m.find("b")->second << '\n';
cout << "a count: " << m.count("a") << '\n';
cout << "b count: " << m.count("b") << '\n';
cout << "traverse" << '\n';
// map<string, int>::iterator it; also possible
for (auto it = m.begin(); it != m.end(); it++) {
cout << "key: " << it->first << " " << "value: " << it->second << '\n';
}
return 0;
}// 출력 결과
size: 3
a: 1
b: 2
a count: 1
b count: 1
traverse
key: a value: 1
key: b value: 2
key: c value: 3- 특정 요소가 존재하는지 유무
if ( m.find("key") == m.end() ) {
// not found
} else {
// found
}- 중복 되는 key가 가능하도록 하고 싶을 때 : multimap 이용
#include <iostream>
#include <string>
#include <map>
using namespace std;
int main() {
multimap<string, int> m;
m.insert(make_pair("a", 1));
m.insert(make_pair("a", 18));
m.insert(make_pair("b", 2));
m.insert(make_pair("c", 3));
m.insert(make_pair("d", 4));
m.insert(make_pair("e", 5));
if (!m.empty())
cout << "size: " << m.size() << '\n';
cout << "a: " << m.find("a")->second << '\n';
cout << "b: " << m.find("b")->second << '\n';
cout << "a count: " << m.count("a") << '\n';
cout << "b count: " << m.count("b") << '\n';
cout << "traverse" << '\n';
// map<string, int>::iterator it; also possible
for (auto it = m.begin(); it != m.end(); it++) {
cout << "key: " << it->first << " " << "value: " << it->second << '\n';
}
return 0;
}size: 6
a: 1
b: 2
a count: 2
b count: 1
traverse
key: a value: 1
key: a value: 18
key: b value: 2
key: c value: 3
key: d value: 4
key: e value: 5- 하나의 key에 여러 value를 저장하고 싶을 때 : map<int, vector<int>> 와 같은 형식 사용
5) tuple
- pair 타입은 2개의 원소만 포함할 수 있지만, tuple은 3개 이상의 원소도 포함할 수 있다.
tuple<int, int, int> my_tuple = make_tuple(1, 2, 3);
cout << get<0>(my_tuple) << endl;
cout << get<1>(my_tuple) << endl;
cout << get<2>(my_tuple) << endl;출력 결과
1
2
3- 참고 : www.crocus.co.kr/598
출처1 : https://plzrun.tistory.com/entry/삼성-SW검정-서티코딩취업준비-자주하는-질문들
출처2 : baactree.tistory.com/29
출처3 : stackoverflow.com/questions/22306949/does-deque-provide-o1-complexity-when-inserting-on-top
출처4 : blockdmask.tistory.com/366
출처5 : is03.tistory.com/65
출처6 : dawnarc.com/2019/09/algorithmstime-complexity-of-vector-set-and-map/
출처7 : https://blockdmask.tistory.com/335
'알고리즘 > 자료 구조' 카테고리의 다른 글
| 백준 15903번 : 카드 합체 놀이 (0) | 2021.01.05 |
|---|---|
| 우선순위 큐와 힙 개념 및 C++ STL (0) | 2021.01.04 |
| C++ STL vector 시간복잡도 (0) | 2020.12.31 |
| 백준 1874번 : 스택 수열 (0) | 2020.12.18 |
| 백준 10845번 : 큐 (0) | 2020.12.17 |

